Computer storage has changed so much over last few decades, in both size and speed terms. We see a lot of amazing performance test results for NVMe drives nowadays. We could copy files much faster from one place to another. But what does it mean for software developers? How fast we shall expect our code to read? The following is some test results I have done in Java.
The data file I am trying to read is the GDELT 1.0 Event database. The file name is: GDELT.MASTERREDUCEDV2.1979-2013.zip, which is 1.01 GB in zip format and 6.12 GB when uncompressed. The reason I picked this file is because it is real data and at the same time big enough.
Old Results
I firstly ran the test with my old desktop in Feb, which has Intel i5 6400 CPU and a SanDisk SSD Plus 1T drive. The drive is using SATA 3. The code is quite simple:
public class LargeFileReadingTest {
public static void main(final String[] args) throws Exception {
long start = System.currentTimeMillis();
int lineCount = 0;
ZipFile zipFile = new ZipFile("C:\\Codes\\temp\\io\\GDELT.MASTERREDUCEDV2.1979-2013.zip");
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(zipFile.getInputStream(zipFile.entries().nextElement())))) {
while (reader.readLine() != null) {
lineCount++;
}
}
long duration = System.currentTimeMillis() - start;
// Expected to be: 87298047
assert lineCount == 87298047;
System.out.println("Duration " + duration);
}
}
When I read the file from zip, it takes 32.326 secs to finish. When I read unzipped file using a BufferedReader with default buffer size (which is 8192), it takes 24.473 secs. When I increase the buffer size to 4096 * 512, it takes 28.618 secs. If I reduce the buffer size to 1024, it takes 22.136 secs. Reading unzipped file directly is about 260 MB/s given the file size, while SATA 3 has a read speed up to 545 MB/s based on data sheet from SanDisk. These test results are based on one off runs, which may not that accurate. But since I already pulled the desktop apart, I cannot really rerun the tests unfortunately. I was hoping to get faster read by reading the zipped file but I suspect it didn’t work because my CPU (i5 6400) is not that fast.
Testing with NVMe
Now that I have new machines I can rerun the tests. I have done three more tests, one with a Lenovo M920q with Intel i7-9700T and Samsung 970 EVO NVMe, another with a NUC11 with Intel i7-1165G7 and Samsung SSD 970 EVO Plus NVMe, and lastly with the same NUC but a different drive, which is WD Black SN750 NVMe. This time I tried to be more accurate. For each test, I run 10 times, instead of just once. The tests are done on Windows 10 version 10.0.19042 and Java version is 14.0.2.
The testing result is as follows. All times are in milliseconds:
| Reading Zip | DefaultBufferSize | 1024BufferSize | 4096Times512BufferSize | |
|---|---|---|---|---|
| M920 | 24894.5 ± 351.7 | 12325.9 ± 460.6 | 15345.6 ± 537.0 | 14294.3 ± 148.5 |
| NUC with Samsung disk | 18861.6 ± 449.1 | 8928.9 ± 256.1 | 10414.3 ± 373.8 | 10569.4 ± 125.6 |
| NUC with WD Black | 18878.2 ± 311.3 | 8666.2 ± 267.3 | 10289.6 ± 401.5 | 10206.0 ± 189.9 |
Reading Zip
Looking at Reading Zip speed, both M920q and NUC11 are slower than DefaultBufferSize case, where unzipped file is read. The faster read with DefaultBufferSize suggests that the bottleneck when Reading Zip is on CPU rather than disk IO. Since the code is single threaded, the performance differences are linked to the single core max turbo frequency:
| CPU | Max Turbo Frequency | Reading Zip Performance | |
|---|---|---|---|
| Old Desktop | i5 6400 | 3.30 GHz | 32326 |
| M920 | i7 9700T | 4.30 GHz | 24894.5 |
| NUC | i7 1165G7 | 4.70 GHz | 18869.9 |
Trying to fit these 3 data points linearly:
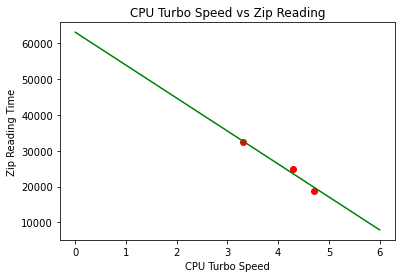
Using this simple fitted model, naively, to achieve the same speed as DefaultBufferSize on M920, I would need a CPU with max turbo speed of 5.52 GHz. For NUC, I would need a CPU with max turbo speed of 5.90 GHz. I am not experienced in overclocking and not sure if they are practical or not. But it feels like trading CPU for disk IO on local disk setup doesn’t make much sense.
DefaultBufferSize
Looking at DefaultBufferSize value by itself, it is interesting to see that NUC is about 28% faster compared to M920 while the drive has comparable sequential read performance:
| SSD | Data Sheet Sequential Read | Observed Read Performance |
|---|---|---|
| Samsung SSD 970 EVO | Up to 3,400 MB/s | 519.23 MB/s |
| Samsung SSD 970 EVO Plus | Up to 3,500 MB/s | 716.77 MB/s |
| WD Black SN750 | up to 3,400 MB/s | 738.50 MB/s |
Without any hard evidence, I suspect M920 is slower because I use it as a server and there are 4 VMs it is running. The 970 EVO is the only drive which runs OS and everything else. Something else is slowing down it. This is partially supported by the fact that NUC running 970 EVO Plus is slightly slower than WD Black because the WD drive is the secondary drive while 970 EVO Plus runs the OS.
Perhaps a more important question to ask is can I read faster? Naively, I tired to run multiple reads in different threads. If the bottleneck is disk in single thread scenario, the read speed per thread shall be slowed down proportional to the number of threads. Testing on M920 with 2 threads, the average time to read with DefaultBufferSize is 13436.2 milliseconds. This gives 952 MB/s. So, it is not the disk which is the bottleneck.
Then is it the java code (BufferedReader and InputStreamReader) which is less optimal? Some Googling leads me to Martin’s blog, which is quite interesting. However, I will let my SSD to have some rest and give this a spin in another day.
Last modified on 2021-07-22